从 Commit 到 Branch,一文明白 git 到底怎么回事
git 令人疑惑
git 是我们每天都要用的工具——它通常按照我们的直觉运作。例如你和你的同事在不同的分支上修改文件系统,然后通过 git 合并这些改动,从而实现高效的团队合作 —— 不需要手动合并改动、不需要时时刻刻的网络连接、不需要复杂的即时办公系统。从直觉上,我们修改工作区,然后用 git add . 将改动暂存,再用 git commit 提交这个改动。我们通过 git push 将本地分支同步到网络,git pull 将网络分支同步到本地,通过 git merge 或者 Github 的 Pull Request 合并不同的分支。
So far so good。Git 按照我们预想的行为工作,把不同的改动进行合并。但是 Git 有时候会给出令人疑惑的报错,我们会遇到莫名其妙的 Merge conflict,似乎 git 一下丧失了“智能”。众所周知,git 并非诞生在神经网络和人工智能的时代,它到底是怎么自动化且高效地记录、汇总我们的代码的呢?我们必须从 git 的原理入手才能理解 git 的行为,从而理解 git 为什么有时候“抽风”,并且100%自信地做好项目的版本控制。
git 用 blob 和 tree 为文件系统建模
众所周知,文件系统由 file 和 folder 组成。一个 folder 可以含有一组 folder 和 file。在 git 内部的数据结构中,blob 对应文件系统的 file,而 tree 对应文件系统的 folder。
blob 和 tree 都属于 git object。他们除了记录了文件或文件夹的名字、内容、权限之外,还被关联到 Object ID —— 这是 git object 和普通 file system 的不同之处。OID (Object ID) 是一个固定长度的哈希值,它可以唯一确定 blob 和 tree 的内容。对于 blob 而言,OID 是文件本身信息的哈希;对于 tree 而言,OID 是它的子 object 和它自身信息的哈希。
例如如下的工作区:
.
├── bak
│ └── text.txt
├── new.txt
└── test.txt
它对应如下的 tree:
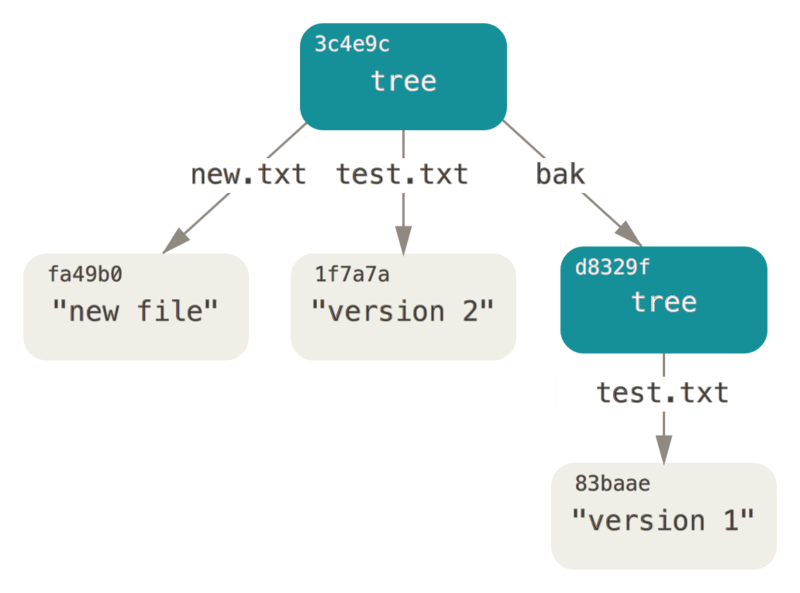
我们可以通过 git 的命令来观察这个 tree (master^{tree} 是当前 commit 根目录的特别名称):
git cat-file -p master^{tree}
040000 tree 05c0975a83dea6d0fec8de069f941e21ab92815b bak
100644 blob 1271944b7e20c7a2cc2708dba5cf8370147d77d4 new.txt
100644 blob 55af8e5b36d666efb8281535bd98fe0f84275347 test.txt
git cat-file -p 05c0975a83dea6d0fec8de069f941e21ab92815b # 05c097... 是 bak 文件夹对应的 OID
100644 blob e32092a83f837140c08e85a60ef16a6b2a208986 text.txt
注意到第三列形如 e32092a... 的东西就是 git 计算的 OID。git cat-file -p OID 可以根据 OID 去查询这个 object 的内容。强烈建议在电脑面前的读者选择一个 git 仓库试验一下。
commit 是 tree + parents + log
tree/blob 看起来只是把一般文件系统做的事情,重新做了一遍,令人不知所云 —— 我们很快就能看到它在 commit/branch 中的应用,从而理解 git 为何要引入 tree 和 blob。
假设我们现在在 master 分支,它的 commit 历史如下:
master: A (HEAD)
当我们使用 git commit 的时候,我们指定了要提交的 tree(来自当前工作区的根目录)、默认了当前的 HEAD 是下一个 commit 的 parent,并且提供了作者和 commit message。git commit 运行后,我们获得了含有上述信息的新 commit,并且 HEAD 被设为了当前的 commit。
master: A -> B (HEAD)
可以看到,commit 的结构暗含了版本管理必备的信息 —— 我们现在在哪个版本 (tree),我们这个版本的上一个版本是什么 (parent commits),我们在这个版本有哪些更新(commit message)。
当进行 Pull Request 或者等价的 git merge 的时候,一个 commit 可以有多个 parent commit。我们之后会探讨 merge 时具体发生了什么。
注意,commit 对应的 tree 可以指向“只属于”当前 commit 的文件,也可以指向之前 commit 的文件。所以,当我们添加了一个新文件的时候,我们实际上只需要创建从该文件出发到根节点的 object,而保留无关的 object,从而节约大量空间。多次 commit 的结果如下图:
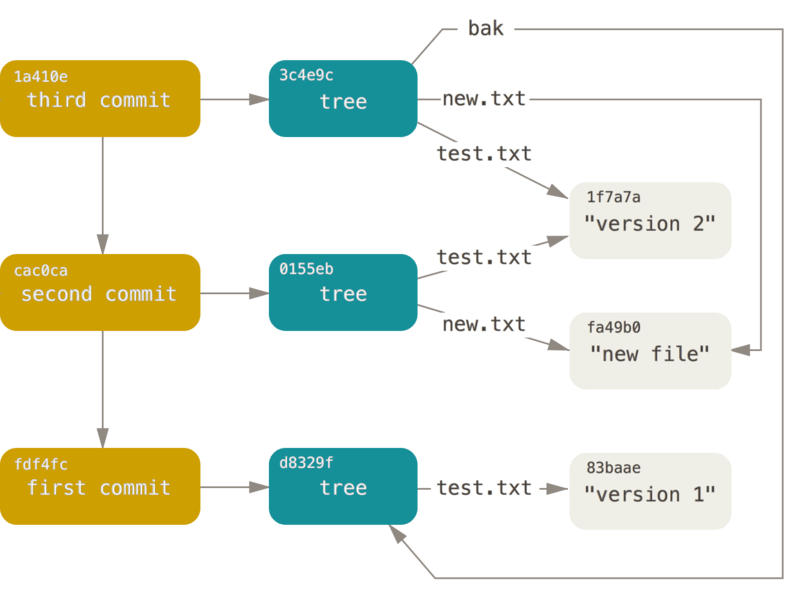
注意内容为 version 2 的 test.txt 被 OID 为 3c4e9c 和 0155eb 的树指向了两次,而 bak 对应的 tree 甚至可以指向 first commit 的根目录,因为两者是完全相同的!
branch 是从最后一个 commit 出发得到的 commit 链表
在这之前,我们介绍的都是 git 中“不可变”的部分:我们进行版本管理的过程中,每个版本都是创建一个新的 commit,这个 commit 含有相关的 log 和 parent 信息,以及一个新的 tree,这个 tree 指向了源码,而不能去修改一个已经建好的 commit 和 tree/blob。
但是这无法满足我们需要知道“哪个版本是最新的”这一需求。git 的创造者说:那我们只要规定若干“变量”,叫他们 master/main/dev/hotfix,然后把它们的值定为某个 commit 的 OID,不就 OK 了?于是,branch 的概念浮出水面:每个 branch 对应一个最新的版本,多个 branch 对应源码不同的分支的最新版本。
branch 自然地包含了 commit 的历史:除了第一个 commit,每个 commit 都至少有一个 parent,它的第一个 parent 被定为“它所在 branch 的上一个 commit”。沿着这条路走,我们就有了一条 commit 的链表,从最后一个,到第一个 commit。相信对于掌握了链表数据结构的同学,是非常容易理解的。
HEAD -> HEAD^ -> HEAD^^ ... -> first commit
merge 是一个特别 commit
假设我们有两个 branch: otherbranch 和 master:
otherbranch
|
X <- Y <- Z
/
A <- B <- C <- D <- E <- F <- G
|
master
|
HEAD
那么当我们进行 otherbranch -> master 的 PR,或者在 master branch 上执行 git merge otherbranch 时,我们在做什么呢?
- 计算 merge base —— 它是我们的“出发点”,在这里是
C。 - 计算
otherbranch到 merge baseC的差分diff(C, Z),计算master到 merge baseC的差分diff(C, G)。 - 得到新的 commit
M,M是diff(C, Z)和diff(C, G)同时作用于C的结果。master现在指向了M,M的第一个 parent 是G,第二个 parent 是Z。
otherbranch
|
X <- Y <- Z <--------\
/ \
A <- B <- C <- D <- E <- F <- G <- M
|
master
|
HEAD
diff 的具体计算方式我不是很清楚,也不是很清楚“将两个 diff 同时作用于一个 commit”时究竟发生了什么。但是实际上它不影响我们理解 git 的工作模式。事实上当 git 自己找不到一个合理的办法“同时执行两个 diff” 的时候,他会提示出现 “merge conflict”,并请求人类的智慧来决定 M 是什么。我们要知道,diff 的计算和 apply,实际上都是启发式的,并没有标准的答案,也并不总能保证符合预期。合并的结果如何,永远只能通过软件的测试结果来评价。
重要的是 merge base 是如何找到的 —— 这决定了我们让 git 在尝试自动合并的时候,以哪个 commit 作为参考!如果我们选择的参考不合理,git 以其贫瘠的智慧将不停地报出“merge conflict”,即使你并没有刻意地制造 conflict!下面我们将举出简单的例子。
merge base 的定义非常简单:它是两个 branch 的“最佳公共祖先节点”。所谓最佳,就是这个公共祖先节点的位置“最低”,它不是其他公共祖先节点的祖先。例如:
o---o---o---B
/
---o---1---o---o---o---A
1 是 A 和 B 的 mergebase。这里,1 是 A 的祖先,也是 B 的祖先。1 的父节点也是 A 和 B 的公共祖先,可惜它不是最佳的。
接下来是一个实用的例子:
otherbranch
|
X <- Y <- Z <--------\
/ \
A <- B <- C <- D <- E <- F <- G <- M
|
master
|
HEAD
master 分支和 otherbranch 在 M 处进行了 merge。问这时 otherbranch 和 master 的 merge base 是哪个?
答案是 Z。因此,如果 otherbranch 再次向 master 进行 merge,将对 Z 应用 diff(Z, M) + diff(Z, Z)。diff(Z, Z) 一定是空的。因此,无论 diff 如何实现,结果都将是 M 自身!
接下来我们看一个稍微复杂的例子:
o---o-----------N dev
/ /
---A---o---o---M / master
\ / /
o---B---- hotfix
dev 分支和 master 分支在 A 处分叉,然后 hotfix 在 master 分支分叉。接下来 我们将 hotfix 分支在 B 点分别和 dev 和 master 进行 merge 操作。这之后,dev 和 master 的 merge base 是谁呢?
答案是 B,而不是 A,这是 git 的算法决定的。
值得注意的是,公共祖先可以沿着 first parent,也可以沿着其他任何一个 parent。实际上,这种操作是令人困惑的——这意味着,如果之后执行一次 dev -> master 的操作,我们将以一个既不在 dev 也不在 master 上的 commit 作为 merge base。所以我个人更接受先将 hotfix 合入 master,再将 master 合入 dev,这样保持了 master 和 dev 的 merge-base 保持在两者分支上。
squash merge 是特别的 merge
我们回到刚才的例子:
otherbranch
|
X <- Y <- Z
/
A <- B <- C <- D <- E <- F <- G
|
master
|
HEAD
如果我们在 merge 的时候,选择了 “Squash and Merge” 会发生什么呢?和普通的 merge 一样,一个以同样方式得出的 commit M 会被添加到 master,但是这个 M 没有到 Z 的 parent!
otherbranch
|
X <- Y <- Z
/
A <- B <- C <- D <- E <- F <- G <- M
|
master
|
HEAD
可以说,master “忘记”了 M 来自 otherbranch 的贡献,但好处是我们可以忘记 otherbranch 的存在,简化了我们 git 仓库的历史。
squash 并不是没有害处 —— 如果我们继续在 Z 上进行 commit,我们的 merge base 会依然是 C,而不会像普通 merge 一样改为 Z。因为我们失去了 Z 到 M 的联系,将会导致 git 可能无法理解我们改动的意图。
假设 diff(C, Z) 是将某一行改成了文本 Z,接着在 otherbranch 将该行改动为 X,然后我们将 otherbranch merge 到 master。
注意在 G <- M 中,我们已经将该行改为 Z 了,但是新的 merge 中,我们发现这一行(从 C 的情况)变成了 X,这会导致一个 conflict。这完全是因为我们的基准是 C 导致的。
但是在普通 merge 时,我们的 base 是 Z,因此如果进行同样的操作,我们知道是这一行从 Z 变成了 X,因此不应该有任何 conflict。
(当然了,这是我们不清楚 git diff 的细节的前提下给出的猜测,但我们终究应该知道,有更好的 base 一定会减少 conflict 出现的几率,这是我们一定能做的)
为了避免这种害处,一般 squash merge 后的 branch 都不会再进行修改了。如果使用 squash merge,一般会进行 feature branch —— 一个 branch 的生命周期仅仅是实现这个 feature 的所需的工作时间。
总结
- git 用 object 对文件系统和版本进行建模,每个 object 有基于其内容的哈希值作为 ID。
- tree 和 blob 分别对应文件夹和文件。
- commit 包含以下信息,每一个 commit 对应一个源码版本和他的历史信息:
- 零个或多个 parent commits;
- 根目录 tree;
- 其他附加信息。
- branch 的实现仅仅是 commit 的指针。
- merge/Pull Request 的实现取决于 merge base 的查找和 diff 算法的实现。
- squash merge 和普通 merge 行为不同,squash merge 会丢失 parent 信息,导致 branch 二次 merge 容易 conflict。
读到最后,相信非常不易。本文只是 git 原理的一角,关于 rebase, cherry-pick 等操作没有涉及,建议阅读参考资料中的文章深入了解。
参考资料
- https://github.blog/2020-12-17-commits-are-snapshots-not-diffs/
- https://www.biteinteractive.com/understanding-git-merge/